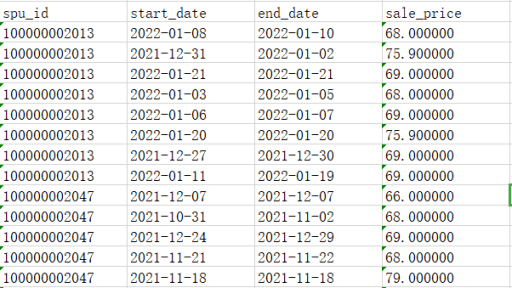
拉链表是数据仓库中特别重要的一种方式,它可以保留数据历史变化的过程,这里分享一下拉链表具体的开发过程。 维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。 这里用商品价格的变化作为例子,具体的开发过程要按实际的来,不能照搬代码,编程重要的是了解背后的思路和原理,而不是ctrl+c和ctrl+v。那对我们学习提升的帮助有限,虽然可能对完成工作的效率帮助很大。 在开始介绍之前,这里的数据仓库的环境是…
书籍下载 数据仓库资料分享,失效可留言处理 链接:关注公众号"张飞的猪",回复"数据仓库",领取电子书 扫描二维码关注: 分享的资料截图如下,共11本。 书籍推荐 从事数仓工作,在工作学习过程也看了很多数据仓库方面的数据,此处整理了数仓中经典的,或者值得阅读的书籍,推荐给大家一下,希望能帮助到大家。建议收藏起来,后续有新的书籍清单会更新到这里。 《数据仓库工具箱(第3版)——维度建模权威指南》 本书会介绍基本知识,然后逐个讨论具体实例内容,最后进行综合总体分析,在内容的结构方…
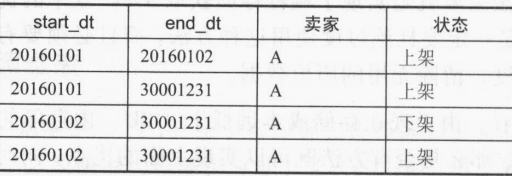
数据仓库的重要特点之一是反映历史变化,所以如何处理维度的变化是维度设计的重要工作之一。缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流逝发生缓慢的变化,与数据增长较为快速的事实表相比,维度变化相对缓慢。阴齿这个就叫做缓慢变化维。 这里介绍的就是这些维度变化的处理,这边整理了一下目前主流的缓慢变化维的处理方式。 原样保留或者重写,这种方式理论上都是取最新的值作为维度的最终的取值,每个维度保留一条数据。这种处理方式是最简单的,直接将原系统的维度同步过来使用就可以,不用做过多的处理。 …
所谓的事实表和维度表技术,指的就是如何和构造一张事实表和维度表,是的事实表和维度表,可以涵盖现在目前的需要和方便后续下游数据应用的开发。 事实表,就是一个事实的集合。事实来自业务过程的度量,基本上以数量值表示。事实表行对应一个事实,一个事实对应一个物理可以观察的事件,例如,再零售事件中,销售数量与总额是数据事实,与销售事件不相关的度量不可以放在同一个事实表里面,如员工的工资。 事实表是实际发生的度量,对应的,这些度量我们可以分为三中类型:可加、半可加、不可加。可加性度量可以按照与事实表关联的任意维度汇总。半可加度量…
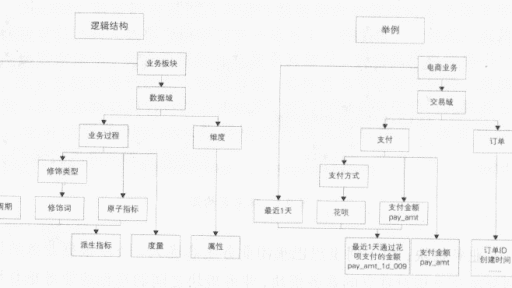
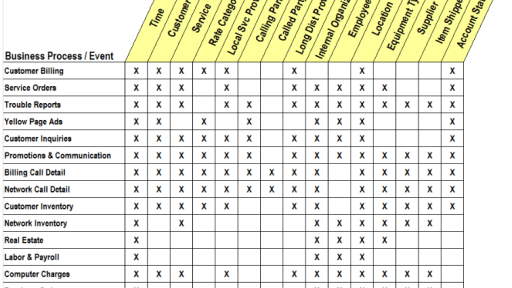
规范设计在这里取《大数据之路:阿里巴巴大数据实践》中的定义,这里记录一下本人对这一块自己的理解。 规范定义指以维度建模作为理论基础 构建总线矩阵,划分和定义数据域、业务过程、维度、度量 原子指标、修饰类型、修饰词、时间周期、派生指标。 所谓的规范的定义,简单理解,如果把数据当作货物,那就是货物的分类,以及对应相关的属性,比如生产日期,某个原料的含量等,我们可以把相近或者相同货物,按照一定的规律,放在一起,方便入库与出库,需要某个货物按照这些规律就可以,以比较快的速度拉取出来。 一般的规范设计包含一下几个方面:划分和…
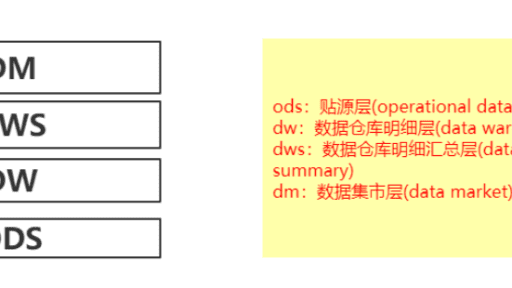
目前主流的数据仓库分层大多为四层,也有五层的架构,这里介绍基本的四层架构。 分别为数据贴源层(ods)、数据仓库明细层(dw)、多维明细层(dws)和数据集市层(dm)。 下面是架构图: 数据分层的目的是:减少重复计算,避免烟囱式开发,节省计算资源,靠上层次,越对应用友好,也对用户友好,希望大部分(80%以上)的需求,都用DWS,DW的表来支持就行,所以ODS层数据不能被DM层任务引用,需要抽取数据到DW,或者DWS。 …
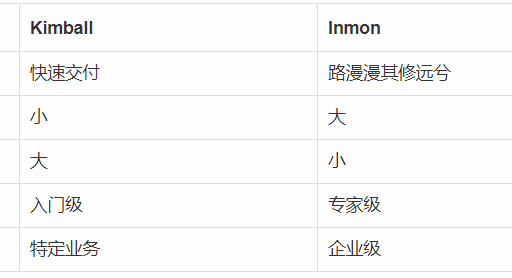
数据仓库主要有四种架构,Kimball的DW/BI架构、独立数据集市架构、辐射状企业信息工厂Inmon架构、混合Inmon与Kimball架构。不过不管是那种架构,基本上都会使用到维度建模。 Kimball的DW/BI架构,可以参考这篇文章 数据仓库(4)基于维度建模的KimBall架构。 独立数据集市架构,采用这种架构的数据仓库,数据以部门为基础来部署,不考虑企业级别的信息共享和集成。也就是各个部门各自按照需要,各自在数据源同步数据,按照各自的标准,对数据进行处理。这种实际上就是没有架构,会造成分析数据的冗余存储…

基于维度建模的KimBall架构,将数据仓库划分为4个不同的部分。分别是操作型源系统、ETL系统、数据展现和商业智能应用,如下图。 操作型源系统,指的就是面向用户的各类系统,如app、网站、ERP、CRM等系统。这一块就是我们数据仓库的数据来源,并且这类数据往往有各自的格式和内容,我们同步过来之后,需要对数据进行清洗和规范化。 ETL系统,指的就是获取、转换、加载的(Extract Transformation and Load)过程以及在etl过程中使用到的数据和数据结构这样的一个过程的集合。也就是包…
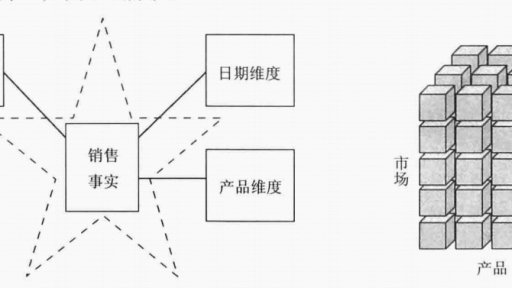
维度建模是一种将数据结构化的逻辑设计方法,也是一种广泛应用的数仓建模方式,它将客观世界划分为度量和上下文。度量是常常是以数值形式出现,事实周围有上下文包围着,这种上下文被直观地分成独立的逻辑块,称之为维度。它与实体-关系建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。 上面的解释看起来是比较抽象,一下子可能不是很容易懂。我们先来了解一下事实和维度,基于上面再来分析一下。 事实,表示的是某一个业…

数据仓库(数仓)与大数据区别,数据仓库(数仓)与数据库的区别,大数据与传统数据库的区别等等,这篇文章带你了解。 我们这里先来说说今天要对比的三个主体,数据仓库、大数据、数据库,在详细说明之前,我们先来说说这三个百度百科上面的定义。 数据仓库:为企业所有级别的决策制定过程,提供所有类型数据支持的战略(数据)集合。 大数据:所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。 传统数据库:一个长期存储在计算机内的、有组织的、可共享的、统一管…

